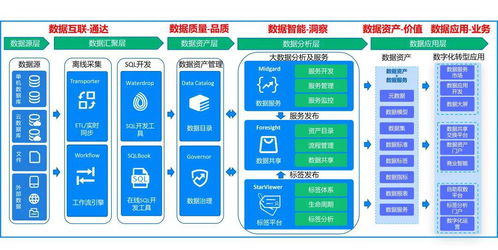
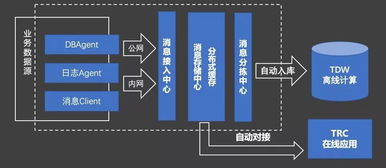
构建企业数据运营体系 数据处理与存储支持服务全解析
在数字化转型的浪潮中,企业数据运营体系已成为提升核心竞争力的关键。一个完善的数据运营体系不仅能够驱动业务增长,还能优化决策流程、降低运营成本。本文将深入探讨构建企业数据运营体系的核心环节——数据处理和存储支持服务,为您提供可操作的实施指南。
一、数据运营体系的基础框架
企业数据运营体系是一个系统工程,涵盖数据采集、处理、存储、分析和应用等多个维度。其中,数据处理和存储作为体系的基石,决定了数据质量和可用性。缺乏高效的数据处理与存储支持,即使拥有海量数据,也难以转化为业务价值。
二、数据处理:从原始数据到可用资产
数据处理是数据运营的核心环节,主要包括数据清洗、整合、转换和加工。
- 数据清洗与标准化:原始数据往往存在重复、缺失或格式不一致等问题。通过自动化工具和规则引擎,对数据进行去重、补全和格式统一,确保数据质量。例如,利用ETL(提取、转换、加载)工具,将多源数据转换为标准格式。
- 数据整合与关联:企业数据通常分散在不同系统中(如CRM、ERP、日志系统等)。通过数据整合技术,打破数据孤岛,建立统一的数据视图。例如,通过主数据管理(MDM)系统,实现客户、产品等核心数据的唯一标识和关联。
- 实时与批量处理:根据业务需求,选择实时流处理(如Apache Kafka、Flink)或批量处理(如Hadoop、Spark)。实时处理适用于风控、监控等场景,而批量处理更适合报表生成和离线分析。
三、数据存储:构建可靠的数据仓库与数据湖
数据存储不仅关乎数据安全,还影响数据访问效率和扩展性。企业需根据数据类型和使用场景,设计分层存储架构。
- 数据仓库:适用于结构化数据,支持复杂查询和业务分析。通过维度建模(如星型模型、雪花模型),将数据组织为主题域,便于OLAP(联机分析处理)。常见工具有Amazon Redshift、Snowflake等。
- 数据湖:用于存储原始和非结构化数据(如图像、日志文件),支持灵活的数据探索和机器学习。数据湖通常基于HDFS或云存储(如AWS S3、Azure Blob Storage)构建,并搭配元数据管理工具(如Apache Hive)实现数据目录。
- 混合存储策略:结合数据仓库和数据湖的优势,构建“湖仓一体”架构。例如,将原始数据存入数据湖,经过处理后加载到数据仓库,兼顾灵活性和性能。
四、支持服务:保障数据运营的持续运行
数据处理和存储离不开配套的支持服务,包括数据治理、安全与运维。
- 数据治理:建立数据标准和管控流程,确保数据的准确性、一致性和合规性。通过数据血缘分析、质量监控工具,跟踪数据生命周期,降低数据风险。
- 数据安全:实施加密、访问控制和审计机制,保护敏感数据。例如,采用角色权限管理(RBAC)、数据脱敏技术,防止未授权访问。
- 运维与监控:通过自动化运维平台,监控数据处理任务的性能和存储系统的健康状态。设置告警机制,及时发现并解决故障,确保服务高可用。
五、实施路径与最佳实践
构建数据处理和存储体系需分步推进:
- 阶段一:需求分析:明确业务目标,评估现有数据资产和技术栈。
- 阶段二:架构设计:选择适合的存储方案(如云原生或混合部署),设计数据处理流水线。
- 阶段三:工具选型与实施:根据预算和团队能力,选用开源或商业工具(如Apache NiFi用于数据流管理,MySQL或MongoDB用于存储)。
- 阶段四:迭代优化:通过监控和反馈,持续优化数据处理效率与存储成本。
结语
数据处理和存储支持服务是企业数据运营体系的命脉。通过构建高效、安全的数据管道与存储架构,企业能够释放数据潜力,实现智能决策与业务创新。本文提供的框架与实操建议,可作为企业数据战略的参考,助您在数据驱动时代占得先机。
(本文为干货长文,建议收藏以备后续查阅。)
如若转载,请注明出处:http://www.xingfuqhd.com/product/12.html
更新时间:2026-06-19 14:52:19